Use a web crawler to generate documentation
If the documentation that you want to add to the AI assistant is already available online, you can crawl the website.
Crawl process
The crawl process is as follows:
- Add the link to the website that contains your documentation.
- The system crawls your website and generates a file.
- Upload the file to the AI assistant's Custom Content section.
For production purposes, prepare the documentation manually for the best results.
Use the unaltered output of the crawler only for demo purposes.
For more information, refer to the following sections.
Guidelines for the website
Guidelines to crawl the website
- Use only HTML website formats.
- If your website uses JavaScript code or APIs to display content, the content quality might be affected.
- If you use links to social media sites, such as Facebook and Twitter, the content quality might be affected.
- The AI assistant uses content only from the link and its pages. It does not use content from other parts of your website.
- Use the top-level link that contains the relevant content.
Example: If you want the assistant to use documentation for the Answers product, addhttps://www.infobip.com/answers.
If you addhttps://www.infobip.com/docs, the assistant uses the documentation for all Infobip products. So, the assistant might not generate an accurate response. - The content scraping stops when one of the following limits is reached:
- A maximum of 7 MB of content is scraped.
- Content is scraped for 2 minutes.
Guidelines for the website content quality
Avoid the following:
- Web pages that contain multiple topics.
- The same content is present in multiple web pages.
- Different definitions of the same concept.
- Incorrect or duplicate information.
- Information about similar products or topics on the same web page.
Configure the crawler
Go to the Crawl tab.
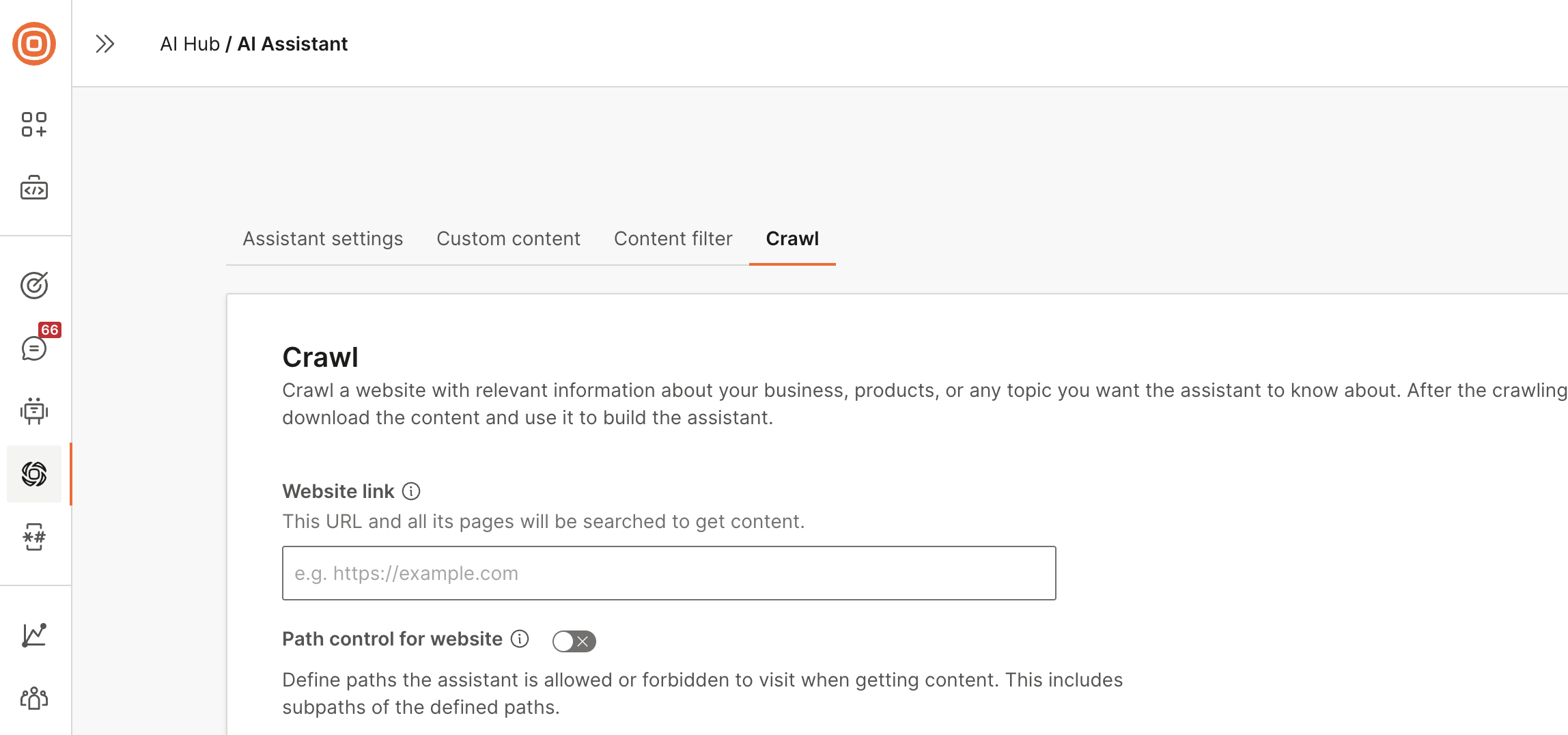
Configure the following:
-
Website link: Enter the link to the website. The assistant searches all pages and subpages of this URL for the content.
-
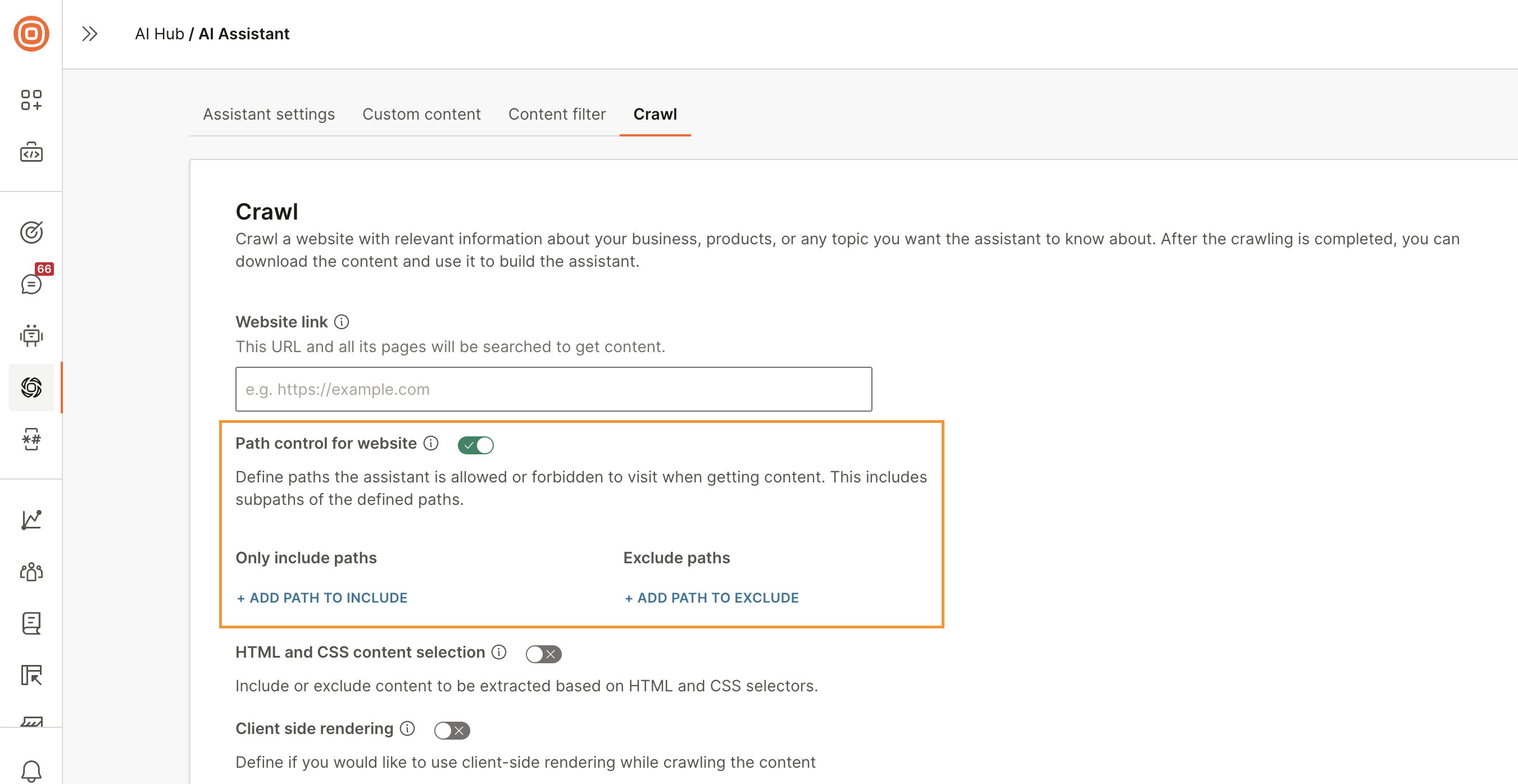
Path control for website (Optional): Select this option to define the paths from which the assistant is allowed or restricted from getting content. You can add an unlimited number of paths.
-
Only include paths: Add the paths from which the assistant needs to look for content. The assistant gets content only from these paths and their subpaths.
-
Exclude paths: Exclude the paths from which the assistant must not get content. The assistant also excludes the sub paths of these paths.
Link Example of including paths Example of excluding paths Description https://www.infobip.com/docs All paths and sub paths in the website link https://www.infobip.com/docs /answers
/momentsAll paths and sub paths in https://www.infobip.com/docs/answers and https://www.infobip.com/docs/moments https://www.infobip.com/docs /people
/conversationsAll paths and sub paths in https://www.infobip.com/docs except the following paths and sub paths https://www.infobip.com/docs/conversations https://www.infobip.com/docs/people
-
-
HTML and CSS content selection: Include or exclude content based on HTML and CSS. Use CSS selectors to identify the desired elements.
Example:
.article__title,.article__body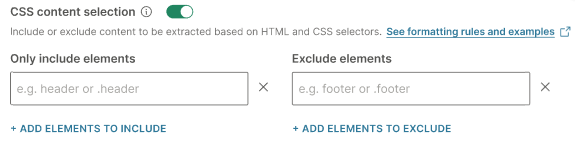
-
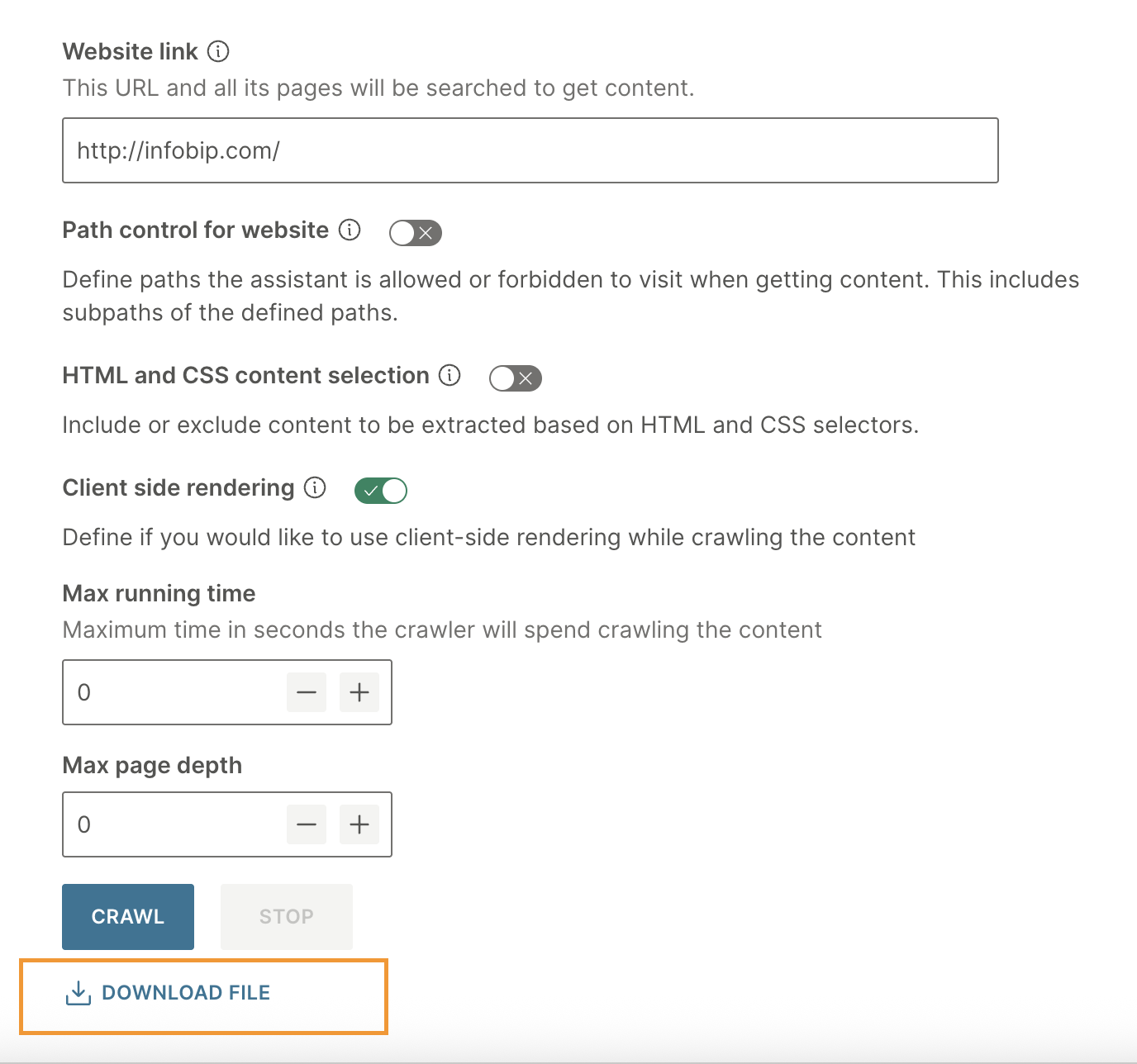
Client-side rendering: Define if you would like to use client-side rendering while crawling the content. Use this for websites that rely heavily on JavaScript to load content dynamically.
-
Max running time: Define the maximum time in seconds the crawler will spend crawling the content.
-
Max page depth: Define the crawl depth. This number refers to the number of clicks or links away from the starting page that the crawler is allowed to explore. A higher crawl depth allows the crawler to access more deeply nested pages within a website.
Launch the crawler
Select Crawl to launch the crawler. Stay on this page until the crawling is complete.
When the crawling is complete, download the .zip file that contains the output.
Add the documentation to the assistant
-
Modify the content of the downloaded file. Refer to the guidelines in the Create your own documentation section.
NoteFor production purposes, prepare the documentation manually for the best results.
Use the unaltered output of the crawler only for demo purposes.
-
Upload the file to the AI assistant. Refer to the Upload the documentation section.